Super Lightweight PDF and DjVu Reader
Table of Contents

Introduction
Have you ever wondered if it is possible to have a universal document reader which is also lightweight in resource consumption?
You might have encountered files in different formats such as PDF, ePub and DjVu. They are very popular and you can convert one into another using either offline tools or online services like https://www.online-convert.com, however in any conversion there is a potential loss of information so one part of you still wants to be able to use the original file, therefore you are left with the question “which software should I use?”. It is of course a matter of personal taste and for me I like lightweight software. I also like the convenience of having a single tool that is capable of managing all my cases in an efficient way.
My requirements:
- view documents in PDF, DjVu and ePub format
- fast startup time (I don’t like to wait for the software to load)
- low resource consumption
- the document reader should not automatically send personal data with the excuse “we collect your data to improve the service”
- preferably cross-platform, but I am almost always on Linux so I need at least Linux support
- support the functionality “invert colors” to read white characters on a black background
There are multiple solutions out there. On Windows there is Sumatra PDF which looks more or less what I need but it does not work under Linux. Okular is the KDE universal document viewer and I have it installed by default with Slackware Linux, but it is not lightweight enough. Last but not least in the category of generic document readers we have Atril: it looks like my tool but it has too many dependencies and it does not come installed by default in my distro.
Xpdf and DjView4 are lightweight but they support respectively only PDFs and DjVu files. Using a single tool for each file format might make sense even though I feel duplicating the UI is a waste of work and different software usually have different keyboard shortcuts.
For ePubs the situation is even weirder since it is basically a zip file with a bunch of XHTMLs and images so we can unzip the archive and use the browser to read the content.
If we dig a little bit more into how they work under the hood, it becomes apparent that PDF and DjVu are very similar in purpose and how they store information in a file. While ePub is a completely different story.
My first conclusion is that a document reader that supports both PDF/DjVu and ePub cannot be as lightweight as I wish since it will end up mixing two completely different rendering engines: a browser and a simpler document viewer. Let’s drop the requirement of supporting ePub. Given the very different file formats, it makes sense to manage each format with distinct software.
For PDF and DjVu there is no reason to not find a solution that supports both file formats and meet also all the other requirements I have.
Fbpdf and Fbdjvu
Let’s see what we find on Slackbuilds.org by searching for “djvu”. There are few results and most of them are tools to convert extract or manipulate DjVu files. One caught my attention and I have also found in a list of recommended DjVu readers: Fbpdf.
From the name looks like it supports also PDFs. Let’s see how lightweight it is. I couldn’t believe at first: it is a very small C project on GitHub consisting of only 3 header files and 5 others of source code in C language. A total of 8 files. But how big each file is it? It might be super long, but to my big surprise the longest is less than 400 lines of code.
Intrigued and fascinated I wanted to try it. Does it work?
Unfortunately my first run was not successful:
$ ./fbpdf myfile.pdf
fb_init(): permission denied
I must have mistakenly removed the read permission from myfile.pdf,
but after checking I don’t see any issue with file permission.
Let’s understand which file it tries to open with strace:
$ strace ./fbpdf myfile.pdf
...
open("/dev/fb0", O_RDWR) = -1
fb_init(): permission denied
...
$ ls -l /dev/fb0
crw-rw---- 1 root video 29, 0 Nov 2 16:10 /dev/fb0
$ id myuser
uid=1000(myuser) gid=1000(myuser) groups=1000(myuser)
Ok, so my issue is that the program is trying to access a
block device /dev/fb0 and my user is not in root or in the group
video. After adding my user to the correct group, logging out and in
again I was able to run the program without errors, but still I didn’t
see the expected output on the screen.
A little bit disappointed I thought to quit my search for the moment and go to sleep (it was late at night). I started the shutdown procedure and for a short moment I saw on the screen the first page of the PDF.
Linux Framebuffer and the X Window System
Puzzled from that unexpected screen I had to understand what was happening in my system. Let’s read what is the description of Fbpdf (README on GitHub):
// https://github.com/aligrudi/fbpdf.git
FBPDF
=====
Fbpdf is a framebuffer pdf and djvu viewer.
...
I remember I heard the word framebuffer before and I know it has to do with Graphics, but I didn’t remember exactly what it was:
// https://en.wikipedia.org/wiki/Linux_framebuffer
The Linux framebuffer (fbdev) is a Linux subsystem used to show
graphics on a computer monitor, typically on the system console.[1]
It was designed as a hardware-independent API to give user space
software access to the framebuffer (the part of a computer's video
memory containing a current video frame) using only the Linux kernel's
own basic facilities and its device file system interface, avoiding
the need for libraries like SVGAlib which effectively implemented
video drivers in user space.
Wow, it looks super cool but the page says also it has been superseded by DRM. If we check the official documentation we see it is still maintained and used: https://www.kernel.org/doc/html/latest/fb/framebuffer.html
When I read about the application of the Linux Framebuffer I clearly saw the big picture:
- when the boot loader loads the kernel in memory and the bootstrap process starts, we see a bunch of text messages scrolling on the screen
- the video card starts in text-mode [1] (it looks like a device that gets a text in ASCII and represents the character on the screen)
- the kernel starts loading the modules and one of them is the driver of the video card
- there is a specific moment during the bootstrap when I see the console clearing all messages, changing resolution and displaying a nicer console with friendly penguins on the first line
- by paying attention to the messages, the screen refresh happens as soon as the text “/dev/fb0” appears
- since I always start my system in runlevel 3 and I do not use any display manager for graphical login, I see the login prompt in this textual command line
- after logging in, I usually run
startxto load the X Window System and use any GUI application - this time I tried to run
./fbpdf myfile.pdfand I saw the PDF correctly rendered.
This discovery opened a new world to me: it is possible to run graphical applications also without Xorg (the default implementation of the X Windows System). I read online it is even possible to browse the web using Firefox (compiled with a special module) and even watch movies (MPlayer supports it)!!!
Of course you cannot do 3D Acceleration using the Framebuffer so don’t expect great performance if you try to watch your favorite action movie. To take full advantage of what the video card has to offer, it is required to run Xorg and use the more advanced driver implemented in it.
How Fbpdf interacts with the Framebuffer
We now have better clarity on what is the Framebuffer and in which context it is used. But how complex is it to interact with it from a program perspective? The magic behind Fbpdf still needs to be revealed.
We know the power of device blocks: we are able to communicate with a device simply using a special file (usually in /dev) and the same API to read/write a regular file. Looks simple enough and it works in most of the cases (think about /dev/zero, /dev/null for example) but some scenarios are more complex and require more parameters. For example to play an mp3 file, in theory, you just need to decompress the stream and perform a copy sample-by-sample to the special file that abstracts the audio card. However, even in the simpler scenario of a single channel (audio mono) you need to set the sampling frequency specific to that mp3. And what happens if another program wants to play another sound while the playback of your mp3 is still in progress?
For the video stream I have no reason to expect a simpler scenario given the nature of an image which is at least a 2-dimensional array.
Checking the code of Fbpdf the drawing function looks as simple as this:
/* ==> From file fbpdf.c */
static fbval_t *pbuf; /* current page */
static int srows, scols; /* screen dimentions */
static int prows, pcols; /* current page dimensions */
static int prow, pcol; /* page position */
static int srow, scol; /* screen position */
...
static void draw(void)
{
int bpp = FBM_BPP(fb_mode());
int i;
fbval_t *rbuf = malloc(scols * sizeof(rbuf[0]));
for (i = srow; i < srow + srows; i++) {
int cbeg = MAX(scol, pcol);
int cend = MIN(scol + scols, pcol + pcols);
memset(rbuf, 0, scols * sizeof(rbuf[0]));
if (i >= prow && i < prow + prows && cbeg < cend) {
memcpy(rbuf + cbeg - scol,
pbuf + (i - prow) * pcols + cbeg - pcol,
(cend - cbeg) * sizeof(rbuf[0]));
}
memcpy(fb_mem(i - srow), rbuf, scols * bpp);
}
free(rbuf);
}
/* ==> From file draw.c */
static int fd; /* FB device file descriptor */
static void *fb; /* mmap()ed FB memory */
...
int fb_init(char *dev)
{
...
fd = open(path, O_RDWR); // path = "/dev/fb0"
...
fb = mmap(NULL, fb_len(), PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
...
}
...
void *fb_mem(int r)
{
return fb + (r + vinfo.yoffset + yoff) * finfo.line_length + (vinfo.xoffset + xoff) * bpp;
}
The code might seem intimidating at first, but most of the operations are related to the algorithm that maps part of a page of the PDF in part of the video memory. The essence of the communication between our code and the Framebuffer can be summarized as:
- open the file /dev/fb0
- use memory mapping for easier access (not strictly required)
- copy the content of a prepared buffer using memcpy()
In conclusion, yes, it is as simple as remembering that a two-dimensional array in C is represented in memory as a monodimensional structure created by concatenating the values horizontally line-by-line.
Read the full content of the file draw.c if you want to learn all the syscalls required to initialize and use a Framebuffer. It is worth noting that the operating system has done a wonderful job in abstracting the hardware. The price that we pay in order to have a hardware-independent abstraction is that we cannot use any specific feature of the video card, therefore all the 2D and 3D hardware accelerated features cannot be used.
Dig deeper in Fbpdf
Up to this point we understood how simple can be to interact with the video card leveraging the Linux Frambuffer. But a document reader requires so many other functionalities and how is it possible to do it only in so few lines of code? It must depend on so many libraries.
Let’s open the Makefile to understand the structure of the project better:
PREFIX = .
CC = cc
CFLAGS = -Wall -O2 -I$(PREFIX)/include
LDFLAGS = -L$(PREFIX)/lib
all: fbpdf fbdjvu
%.o: %.c doc.h
$(CC) -c $(CFLAGS) $<
clean:
-rm -f *.o fbpdf fbdjvu fbpdf2
# pdf support using mupdf
fbpdf: fbpdf.o mupdf.o draw.o
$(CC) -o $@ $^ $(LDFLAGS) -lmupdf -lmupdf-third -lmupdf-pkcs7 -lmupdf-threads -lm
# djvu support
fbdjvu: fbpdf.o djvulibre.o draw.o
$(CXX) -o $@ $^ $(LDFLAGS) -ldjvulibre -ljpeg -lm -lpthread
# pdf support using poppler
poppler.o: poppler.c
$(CXX) -c $(CFLAGS) `pkg-config --cflags poppler-cpp` $<
fbpdf2: fbpdf.o poppler.o draw.o
$(CXX) -o $@ $^ $(LDFLAGS) `pkg-config --libs poppler-cpp`
I was expecting a very long file, but it is very simple. I like very much the simplicity reached by the author of this program. He truly understands the KISS principle (Keep It Simple, Stupid).
As we see the project consists of 3 executables:
- fbpdf: a document reader that use the library MuPDF [2]
- fbdjvu: a DjVu reader that use the library DjVuLibre [3]
- fbpdf2: the same as fbpdf but it use the Poppler library [4] (extracted from Xpdf)
From the Makefile it is clear now that the file fbpdf.c is the main program and it is used in all the executables. The file draw.c abstract the framebuffer (also this one is used in all the executables). The last component is specific to the library used to render the desired document and implement the functions declared in doc.h.
It is well known that C is not an object-oriented language and even though we could argue that it is possible to implement objects in C (check for example GObject as part of GLib [5]), the use of that style can lead to unnecessary complications. It’s better to use C++ (which is compatible with C) if you feel you are missing Object Oriented Programming.
So how can we structure properly a C project? Is it possible to create only simple applications or is it suitable also for big projects?
The existence of a very big and complex program almost entirely written in C, like the Linux kernel, should wipe out any doubts. Other examples can be FFMpeg, MuPdf, Apache HTTP Server and so on.
Most of the OOP design principles can still be applied to procedural languages like C simply using a substitution of terms:
- instead of talking about classes, we can talk about modules (a single file .c)
- the concepts of private attributes and public methods become static variables and static functions
- interfaces are functions declared in header files
One important difference, if we use the map above, is that modules are like Singleton instances so we cannot have two modules with different states. The map above is probably the simplest form of structuring a C project because to manage different states we have to introduce concepts like structs and handles, but this adds an additional layer of complexity to our application. Following the KISS principle we have only one UI, one Framebuffer and one library depending on the file format (Poppler, MuPDF or DvVuLibre), so it makes sense to avoid packing the static variables in a struct that needs to be carried over in every function call.
Let’s see a diagram of the organization of Fbpdf:
| Modules |
|---|
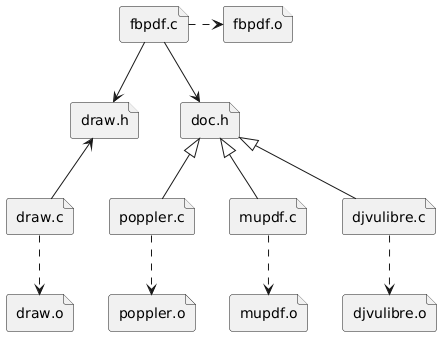 |
| Executables | ||
|---|---|---|
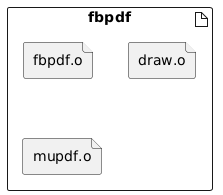 |
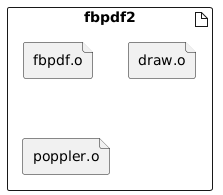 |
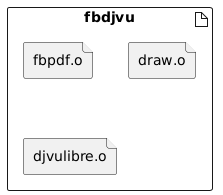 |
(Source code of PlantUML diagram in Appendix)
As we can see from the diagrams the Single Responsibility Principle is followed: each module manages a different aspect of the application.
Loose coupling is achieved by modules depending on interfaces and not concrete implementations (Dependency Inversion Principle). This concept is especially evident when we look at the interface in doc.h and its different implementations.
Note the files mupdf.c, poppler.c and djvulibre.c are Adapters or
Connectors for the corresponding libraries: mupdf.c, for example,
translates the
specific API of the library MuPDF in the API defined by doc.h.
The code looks very readable with functions not having many parameters. The downside of this simplicity are:
- it is not thread-safe because multiple threads would try to access and change the same static variables
- we need to have multiple executables to support different file format
Point one brings the question: do we need multithreading in this application? Since it is a document reader most of the time of this application will be spent waiting for user inputs (a very slow event compared to CPU frequency). The only part that might benefit from multi-threading is when the library renders a page, so it might be useful only internally in the library.
The second point looks like creating a redundancy, but since the source code of fpdf.c and draw.c is shared in all the 3 executables there is no real code duplication. If we really want to have the convenience of having a single command that is able to manage both PDF files and DjVu files we can develop, for example, a very simple shell script that invokes fbpdf or fbdjvu depending on the file extension.
Recap of the design principle followed in Fbpdf
useful for any C project
- absence of conditional compilation (#ifdef) [6]
- minimizing the number of function parameters using static variables at the module scope
- segregation of responsibilities in different modules (or translation units)
- simple Makefile (no need to use CMake)
- keep minimal the public interface of a module (declared in header files)
- if multiple implementations are possible, do not implement dynamic loading of different libraries, but do create multiple executables (each of them links a single static library that implements the defined interface)
- if multithreading is not necessary, do not implement it
- if managing different states is not required, do not implement handlers
- hide the complexity of big libraries defining simple interfaces
Using C++ libraries in C programs
Another interesting thing we can learn from the project is that it is completely possible to use a C++ library in a C program:
- use the C compiler to create object code of the translation units of C code
- use the C++ compiler for pure C++ code
- then the trick is to define an adapter (or connector) where the C++ objects are wrapped into C functions
- to avoid name mangling the adapter must declare the public functions
with the statement
extern "C"and the C++ compiler needs to be used - at this point all the object codes are linkable because the C part will depend only on the adapter
Forking the project: support multiple graphical outputs
Now that we demystified how a document reader can be implemented we understand that the specific library of that file type is capable of rendering a page of the document in a bidimensional array of pixels and then we can use it to show graphical output.
Any GUI toolkit, for example Gtk, Qt, FLTW or wxWidgets, is capable of creating a window and displaying an image. Adding support to this program should be as easy as abstracting the framebuffer to a generic module that is capable of displaying a given image.
This is an idea for a fork of the project that supports Xorg without losing its wonderful characteristic of being lightweight.
If we are looking for a keyboard-driven UI we can think of pushing it even further and keep the dependency only on the library SDL (Simple DirectMedia Layer). This lightweight library is capable of managing a window and displaying images on it and it is used heavily in Video Games.
Before using it we need to think if a GUI application can be implemented efficiently with SDL. Both kinds of applications have at least a window and an event loop which decide how to update the screen on every loop. However a video game usually is very computationally intensive and needs to refresh its state multiple times per second, even in the absence of user input. On the other hand a GUI application sits idle most of the time until the user gives some input.
Let’s see what are the functions available in SDL to receive events (like mouse click, keyboard pressed, etc):
// https://wiki.libsdl.org/SDL2/SDL_PollEvent
/*
* == Description ==
* Poll for currently pending events.
*
* == Return Value ==
* (int) Returns 1 if there is a pending event or 0 if there are none available.
*/
int SDL_PollEvent(SDL_Event * event);
// https://wiki.libsdl.org/SDL2/SDL_WaitEvent
/* Wait indefinitely for the next available event. */
int SDL_WaitEvent(SDL_Event * event);
Since SDL_WaitEvent will block the program until an input is
received, we can efficiently implement
the event loop for our GUI application.
Checking on the internet the following project looks like a good starting point:
// https://github.com/rofl0r/SDLBook
=== SDLBook - a tiny djvu/pdf eBook reader ===
=> Why?
Since there are no djvu readers with reasonable dependency
requirements (i.e. GTK+2, X11, SDL1 or 2, framebuffer) available, I
decided to write my own, by taking a firm glance at what djvulibre's
ddjvu utility does and rendering to a video buffer instead of a
file. I'm not interested in installing heavy-weight GUI toolkits such
as QT4,5,GTK+3,4 etc just for a simple eBook reader. Nor in installing
python3 just to run someone's meson build recipe.
Looks like that someone else has already had my idea. However in the description there is something weird: how can it support also ePub?
It must be the library MuPDF which supports many different file formats. The page on Wikipedia confirms my hypothesis:
// https://en.wikipedia.org/wiki/MuPDF
MuPDF is a free and open-source software framework written in C that
implements a PDF, XPS, and EPUB parsing and rendering engine.
...
A number of free software applications use MuPDF to render PDF
documents, the most notable being Sumatra PDF.
Look at the last line, looks like my favorite document reader under Windows is actually a frontend for the library MuPDF.
I remember using MuPDF in the past, but the library was so huge that I decided it wasn’t lightweight enough. Therefore SDLBook is a tiny application but depends on a huge one. And interestingly enough it does not implement a DjVu rendering so it still requires DjVuLibre as a dependency.
Therefore there is still space for a fork of Fbpdf that substitutes the framebuffer with SDL and removes the dependency from MuPDF.
Forking the project: add support for scrolling two pages per screen
The second idea I had is to implement a custom scrolling of the document based on the following case: sometimes a single page on a PDF is made of two printed pages in a book. To address this issue I used to play with the PDF extracting the images, splitting them and reassembling a new PDF. It was a fun project, I learned a lot about Imagemagic [7], Ghostscript [8] and other tools, but I have to learn another one for DjVu documents. Given how simple it is to create a document reader we can implement a different solution: fork Fbpdf and implement a custom scrolling mechanism:
- the zoom of the page is initially set such that half of the page is as wide as the screen
- when we press space it will scroll down as much as the height of the screen
- when we reach the bottom of the page, we jump to the second half of the page on the top right
- when we reach the bottom right it’s time to switch to the next page starting again on the top left
Conclusions
In this article we discovered how a simple document viewer can be implemented, we learned about the Linux Framebuffer and we understood what are good principles to follow to structure a program written in C. We then proposed a couple of forks of the project and how they can improve the user experience.
References
[1] https://en.wikipedia.org/wiki/Text_mode
[3] https://djvu.sourceforge.net/
[4] https://poppler.freedesktop.org/
[5] https://docs.gtk.org/glib/
[6] https://en.wikipedia.org/wiki/Conditional_compilation
[8] https://www.ghostscript.com
Appendix
To create the diagrams we used PlantUML. The following are diagrams and source code.
' PlantUML Modules Diagram
@startuml
file fbpdf.c
file fbpdf.o
fbpdf.c .> fbpdf.o
file draw.h
file draw.c
file draw.o
file doc.h
file poppler.c
file poppler.o
poppler.c ..> poppler.o
file mupdf.c
file mupdf.o
mupdf.c ..> mupdf.o
file djvulibre.c
file djvulibre.o
djvulibre.c ..> djvulibre.o
draw.h <-- draw.c
draw.c ..> draw.o
doc.h <|-- mupdf.c
doc.h <|-- poppler.c
doc.h <|-- djvulibre.c
fbpdf.c --> draw.h
fbpdf.c --> doc.h
@enduml
' PlantUML Diagram
@startuml
artifact fbpdf {
file "fbpdf.o"
file "draw.o"
file "mupdf.o"
}
@enduml
' PlantUML Diagram
@startuml
artifact fbpdf2 {
file "fbpdf.o"
file "draw.o"
file "poppler.o"
}
@enduml
' PlantUML Diagram
@startuml
artifact fbdjvu {
file "fbpdf.o"
file "draw.o"
file "djvulibre.o"
}
@enduml